Op 31 maart 2023 heeft de Italiaanse toezichthouder voor gegevensbescherming, Garante per la Protezione dei Dati Personali, een tijdelijk verbod tegen OpenAI's ChatGPT voor het gebruik van persoonlijke gegevens van miljoenen Italiaanse burgers die werden gebruikt voor de trainingsgegevens van de AI. Deze gebeurtenis opende de sluizen voor regelgevend onderzoek van andere Europese toezichthouders en heeft het misbruik van persoonlijke gegevens van machine-learning algoritmen in de schijnwerpers gezet.

Hoewel GDPR betrekking heeft op cruciale aspecten van gegevensprivacy en -bescherming, wordt niet specifiek ingegaan op de complexiteit en potentiële bedreigingen van AI-systemen. Laten we eens onderzoeken op welke manieren GDPR dit hiaat in de regelgeving aanpakt en wat de toekomst in petto heeft voor gegevensprivacy.
Welke dilemma's stelt AI voor de privacy?
AI-taalmodellen, zoals GPT-3, hebben gegevens nodig om getraind te kunnen worden in het schrijven van tekst, het ontdekken van correlaties, het doen van voorspellingen, het verbeteren van hun prestaties en nog veel meer. Deze modellen verwerven hun kennis via een combinatie van methoden, waaronder het scrubben van het internet voor informatie, gegevens van licenties van derden en materiaal dat gebruikers invoeren via chats. Dit omvat ook persoonlijke gegevens van EU-burgers die openbaar beschikbaar zijn.Echter, volgens GDPR, Dit betekent niet dat ze vrijelijk kunnen worden gebruikt om AI-modellen te trainen. Artikel 6 van de verordening stelt dat persoonsgegevens waarmee een persoon direct of indirect kan worden geïdentificeerd, niet zonder rechtsgrond mogen worden verzameld, opgeslagen of verwerkt, tenzij er een toereikende rechtsgrond is. Tijdens de trainingsfase van de AI-modellen werd individuen echter geen toestemming gevraagd voor het gebruik van persoonsgegevens. In bijna alle gevallen was er geen manier om te weten wat de AI-systemen online uitwisten.
"Een groot deel van de gegevens op internet heeft betrekking op mensen, dus onze trainingsinformatie bevat incidenteel persoonlijke informatie." ~ OpenAI
Een andere kwestie is het recht om vergeten te worden. Artikel 17 van GDPR, vaak bekend als het "recht op wissen" of "recht om vergeten te worden", geeft mensen het recht om te vragen dat hun persoonlijke gegevens in bepaalde situaties worden verwijderd. Kunnen AI-taalmodellen persoonlijke gegevens van een individu vergeten?
In een artikel in Forbes, AI-expert en sociaal ondernemer Miguel Luengo-Oroz merkte op dat AI neurale netwerken niet vergeten zoals mensen dat doen, maar in plaats daarvan hun gewichten aanpassen om nieuwe gegevens nauwkeuriger weer te geven. Dit betekent dat de informatie bij hen blijft en de netwerken zich richten op het verzamelen van meer nieuwe gegevens. Het is op dit moment onmogelijk om de wijzigingen die een AI-systeem heeft aangebracht door één gegevenspunt terug te draaien op verzoek van de eigenaar van de gegevens.

Een blik op de zaak ChatGPT en GDPR-schendingen
De recente actie van de Italiaanse toezichthouder voor gegevensbescherming tegen ChatGPT is het eerste geval van een toezichthouder die de privacy problemen rond de ontwikkeling van grote generatieve AI-modellen aanpakt.De Italiaanse Garante heeft vier specifieke GDPR-problemen vastgesteld met betrekking tot ChatGPT. Deze omvatten het ontbreken van leeftijdscontroles om gebruik door personen jonger dan 13 jaar te voorkomen, mogelijke verstrekking van onjuiste informatie over personen, gebrek aan openbaarmaking met betrekking tot gegevensverzameling en het ontbreken van een rechtsgrondslag voor het verzamelen van persoonlijke informatie tijdens de training van ChatGPT.

OpenAI's gebrek aan transparantie over de dataset die werd gebruikt om ChatGPT te trainen heeft ook tot bezorgdheid geleid. Onderzoekers bij Microsoft, de belangrijkste investeerder van OpenAI, hebben toegegeven geen toegang te hebben tot alle details van de uitgebreide trainingsgegevens van ChatGPT. Bovendien resulteerde een datalek in maart 2023 in de blootstelling van gesprekken en betalingsinformatie van gebruikers, wat de positie van OpenAI verder bemoeilijkte.
Toezichthouders, zoals de commissaris voor de Duitse deelstaat Sleeswijk-Holstein, vragen om effectbeoordelingen voor gegevensbescherming en informatie over naleving van GDPR.
Welke andere AI-systemen schonden de regels voor gegevensbescherming?
ChatGPT is niet het enige AI-systeem waarvan is vastgesteld dat het de regels voor gegevensbescherming overtreedt. Hieronder staan nog een paar voorbeelden:-
In oktober 2022 kreeg Clearview AI een boete van 20 miljoen euro van de Franse toezichthouder voor gegevensbescherming, CNIL, voor zijn gezichtsherkenningsdienst die foto's van Franse personen verzamelde zonder wettelijke basis.
In februari 2023 trad de Italiaanse Garante op tegen Replika, een AI-chatbot, met het verzoek de verwerking van gegevens van Italiaanse gebruikers te staken. De bezorgdheid kwam voort uit het ontbreken van een goede rechtsgrondslag voor de verwerking van gegevens van kinderen in overeenstemming met de GDPR.
In mei 2022 legde de Hongaarse autoriteit voor gegevensbescherming de Budapest Bank een boete op van 250 miljoen HUF (665.000 euro) voor het gebruik van een AI-oplossing voor het analyseren van spraakopnames van gesprekken tussen haar klanten en het callcenter. De bank verstrekte vage informatie over de manier waarop de AI-klantgegevens verwerkte en zowel de beoordeling van de gevolgen voor de gegevensbescherming als het papierwerk voor de afwegingstoets waren in strijd met de GDPR.
Hoe kunnen AI-modellen GDPR-compliant worden?
Het Europees Parlement een onderzoek gepubliceerd in juni 2020 getiteld "De impact van de General Data Protection Regulation (GDPR) op kunstmatige intelligentie", waarin wordt uitgelegd hoe een AI-model GDPR-compliant kan zijn.Hierin staat dat een AI-systeem dat persoonlijke gegevens gebruikt, moet worden gecreëerd, getraind en ingezet met een specifiek, wettelijk doel voor ogen. Dit doel moet bekend en duidelijk zijn en in lijn met de missie van de organisatie. Dit moet van tevoren worden ontwikkeld tijdens het planningsproces van het project.
Het gebruik van AI-systemen vereist een legitieme onderbouwing. Deze wettelijke rechtvaardigingen omvatten:
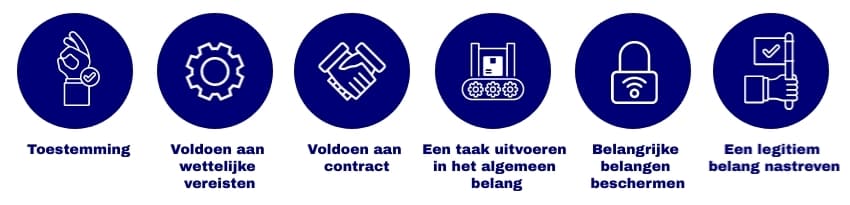
Of het nu tijdens de trainings- of operationele fasen van het AI-model is, het is belangrijk om de verzamelde gegevens legaal te gebruiken. GDPR-bescherming is nog steeds van toepassing voor leerdoeleinden als de leerfase duidelijk wordt onderscheiden van de operationele implementatie en als het enige doel is om de prestaties van het AI-systeem te verbeteren.
Een cruciale regel voor AI-systemen die persoonsgegevens gebruiken, is gegevensreductie. Alleen informatie die relevant, vereist en geschikt is, mag worden verzameld en gebruikt om het gestelde doel te bereiken.
De hoeveelheid gegevens die nodig is om het systeem te trainen moet zorgvuldig overwogen worden tijdens de leerproces. Bedrijven moeten zorgvuldig het type en de hoeveelheid gegevens overwegen, de systeemprestaties testen met nieuwe gegevens, duidelijk onderscheid maken tussen leer- en productiegegevens, pseudonimiserings- of filtermechanismen voor gegevens gebruiken, documentatie bijhouden over de samenstelling en eigenschappen van datasets, routinematig de risico's voor betrokkenen opnieuw beoordelen, gegevensbeveiliging garanderen en kaders voor toegangsautorisatie opstellen.
Wat is de toekomst van GDPR en AI?
De toekomst van GDPR en AI brengt unieke uitdagingen en overwegingen met zich mee. GDPR was primair gericht op het aanpakken van opkomende uitdagingen met betrekking tot het internet, maar bevatte geen concepten met betrekking tot AI. Hoewel de Europese regelgeving geen significante wijzigingen vereist om tegemoet te komen aan AI, zijn er onzekerheden en hiaten in de aanpak van AI-gerelateerde kwesties op het gebied van gegevensbescherming.
Om ervoor te zorgen dat AI-modellen voldoen aan de GDPR, zijn op korte termijn voortdurende discussies, samenwerkingsverbanden tussen autoriteiten en bedrijven en verdere richtlijnen van de EU nodig.




